ChatGPT 一直在反爬虫的方式上下功夫,与第三方 API 开发者斗智斗勇
网页版服务刚出来的时候,是可以直接调用的
进入 2023 年,加了 Cloudflare 的验证,这个时候死掉了一堆第三方 API,好多至今仍然是瘫痪状态
但是通过分析发现,OpenAI 旗下的某个子域名其实在提供着相同的 API 服务,并且没加 CF 验证,于是部分第三方 API 复活
后面这个域名挂了,另一个域名又出来
但是在几天前,这个域名也挂了,接口全部 404,之前的第三方 API 又挂了
留给世人一个难题,如何绕过 CF 验证,方便快捷地使用网页版的服务?
为什么不用公开 API?总体来说,除了 429,ChatGPT 比公开的 API 智能许多,我都用过有发言权
在绕过 CF 反爬虫的机制上,做过很多资料查询,使用过各种姿势,最后无一死在 403,尝试过的方式包括:
请求头修改
这是最低级的方式,通过修改请求头的方式模拟浏览器,失败
设置 Cloudflare Cookie
获取 CF 验证码需要的 Cookie,再在请求的时候加上,失败
JA3 指纹修改
JA3 指纹识别的原理是什么,这里有篇详细的文章:TLS Fingerprinting with JA3 and JA3S
这个发生在握手阶段的 Client Hello 包,通过一些算法来计算出 JA3 指纹,简单来说,一个请求库发出的请求的指纹是固定的,比如我可以知道你的请求是不是来自 cURL,如果是,不合法,直接 403
这个概念有点类似一些库会自动设置 UserAgent,看下日志就能看得到,只是这个 JA3 发生在更底层的协议中
Java 这语言太高级了,在涉及 SSL/TLS 方面的 API 过于复杂,我也缺少相关知识,所以这部分用 Golang 现有的请求库试过,确实能修改到指纹,这样的话,CF 就不知道我们的请求是来自哪个工具了,但是结果仍然是失败
JS 逆向
这个尝试过,不是很懂 JS,太耗时间了,但是如果这个成功了,可能会一劳永逸,如果验证算法更新了,有之前的经验可能随便改改就能适配
自动化测试工具
如果用浏览器去访问,就非常正常,所以想到另一种思路,可以在我们的第三方 API 的基础上,外挂个浏览器
顺其自然就会想到用 Selenium 或者其他类似的模拟浏览器的自动化测试工具,发送请求到我们的 API 的时候,模拟浏览器的点击操作发送请求
但是发现,如果用这些工具打开 ChatGPT,会一直重复出现 CF 验证码,点了之后又出现,再点还出现,无论试了 Selenium、Puppeteer、Playwright,结果都是一样
查询资料发现,其实这些所谓 WebDriver 的实现都会遵循一个规范,就是使用这些工具的时候,获取 navigator 的 webdriver 属性时,会返回 true,而普通浏览器会返回 undefined
那我们是不是可以覆盖它的默认实现,比如自定义 function,当访问这个属性的时候返回 undefined?试过了,不行,包括加一些 ChromeOptions,也不行
1 | var webDriver = new ChromeDriver(chromeOptions); |
正当准备弃坑的时候,发现了一个工具确实能绕过 CF 验证,那就是 undetected_chromedriver
利用这个库能通过 CF 验证进入登录界面,是不是就可以登录,然后操作 dom 模拟数据输入和发送呢?理论上是,我没试,因为突然想到了另外一种方式
XMLHttpRequest
既然这个 undetected_chromedriver 能正常打开页面,而我们的请求都是 XHR,那如果直接通过 JS 操作 XHR 会发生什么?
结果是 200,某种程序上来说,已经成功绕过了 CF 验证
于是开始重写 API,将我们第三方 API 对 ChatGPT 的 API 的调用统统改成 JS
由于我大多写 Java,对于 JS 掌握得不是很好,这个时候遇到一个难题
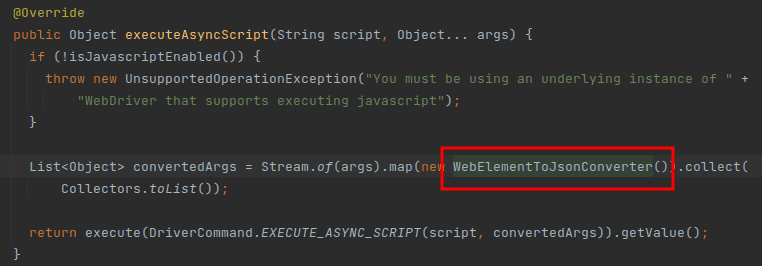
普通的阻塞 API 都可以用 executeScript() 然后通过 return xhr.responseText; 返回响应,但是对话的时候,是 text/event-stream,这个时候如何处理
我知道 Spring 有个 WebFlux 是专门做这个事情的,但是我们又该如何从 JS 那里接管响应数据呢? 接管到数据后,如何又把它们整合到 Flux 里返回呢?
首先是第二个问题的解决方案:
1 | return Flux.create(fluxSink -> { |
如何获取数据?
通过判断 XHR 状态码可以判断数据是不是在传输,比如 LOADING 则目前正在返回对话内容,DONE 则结束
1 | xhr.onreadystatechange = function () { |
问题在于如何跨语言在 JS 里接收到数据再传到 Java 里,Java 可以通过一些脚本引擎执行 JS,但是在这里并不适用
于是想到了 callback 的方式,构造一个 Java 对象传进去,编译成功,但是运行报错,不认识传的对象,这个也正常
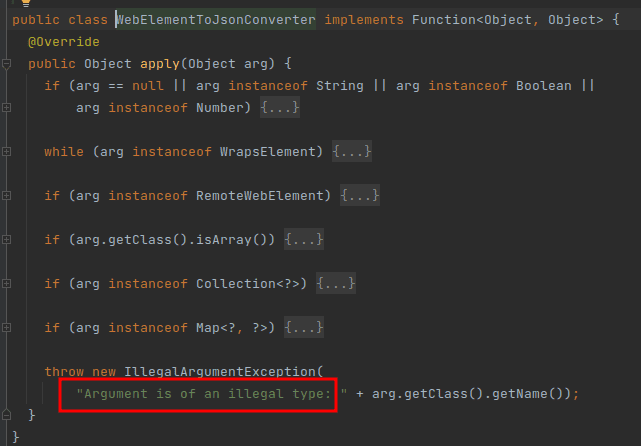
还有别的方法吗,发现有一个 postMessage() 可以用来跨源异步通信,那么不就能满足我们的需求了吗
1 | window.addEventListener("message", function(data) { |
只是不知如何和 XHR 脚本结合起来
因为异步脚本执行要通过 callback 返回数据,而这个 callback 又不能设置在 XHR 发送阶段,因为要频繁 callback 返回数据,这样就会频繁发送请求,所以必须在新的方法里处理,而这个 postMessage() 又需要通过 addEventListener() 的方式获取,所以这里很多矛盾的地方
我也不是很清楚频繁 addEventListener 会发生什么,有尝试过一些判断,如果没有设置过再设置,不好使
同样也不清楚设置多个会不会接收到重复数据,于是代码里先 remove 再 add,不知道合不合理,这个是目前得到的最折中的方法,并且能实现想要的效果,只是异步脚本执行会频繁超时,导致报错,这个还没知道怎么解决(后期已解决这个问题)
undetected_chromedriver
这个库是如何做到不被检测出来的,它在启动的时候修改了 driver 的一些数据,在运行时可以看到会打印在 console 里:
- https://github.com/ultrafunkamsterdam/undetected-chromedriver/blob/master/undetected_chromedriver/__init__.py#L246
- https://github.com/ultrafunkamsterdam/undetected-chromedriver/blob/master/undetected_chromedriver/patcher.py#L91-L99
- https://github.com/ultrafunkamsterdam/undetected-chromedriver/blob/master/undetected_chromedriver/patcher.py#L222-L228
而在运行的时候,修改过的 driver 会放在 ~/.local/share/undetected_chromedriver 里,运行完会删除,可以趁这个时间复制出来供后续使用
1 | ./undetected_chromedriver --help |
在本地测试的时候可以使用 undetected_chromedriver --allowed-ips="" --allowed-origins="*" 来启动,公网要考虑风险
这样就能在 API 外再套一层这个来绕过 Cloudflare v2 验证了
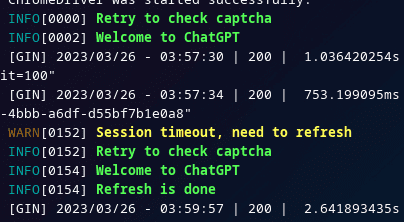
网页版使用的时候,需要频繁刷新,尝试过写个定时器去主动刷新,效果是可以的,只是如果在对话响应处理的过程中刚好碰上自动刷新,对话就会戛然而止,于是改为了被动刷新
如果请求过来,先发一个 XHR 去看下是不是 200,如果是 403,则刷新网页拿新 Cookie,再去请求 API,效果也还行
(后期又改回了定时刷新,并且在对话中不刷新)
打包了一个 Docker 镜像:linweiyuan/chatgpt-proxy-server,开箱即用
尝试过用 Alpine,硬是缺少一些库,于是用回熟悉的 Arch,只是最终镜像有点大,压缩后 413.19 MB,解压后 1.16GB
可过验证码

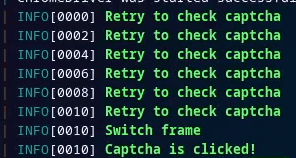
代码
第三方 API:
- 基于 Java 实现:java-chatgpt-api
- 基于 Go 实现:go-chatgpt-api
第三方客户端:
- Java 图形化界面:ChatGPT-Swing
- Go 终端程序:go-chatgpt